I write for trade journals, industry blogs, and LinkedIn on the themes below. Pieces are organized by theme rather than by date, because the questions matter longer than the news cycle.
Featured series
LinkedIn long-form, part one
Why Modern Reliability Engineering Must Expand Beyond Uptime
For eighteen years I have worked inside a discipline that built its identity around a single number. Availability. The nines. Four nines buys roughly 52 minutes of unplanned downtime a year. Five nines leaves about five. We built careers around closing that gap, and the economics made it hard to argue with. ITIC's surveys put the cost of a single hour of downtime above $300,000 for more than 90 percent of mid-size and large enterprises. Around 40 percent say it runs between $1 million and $5 million. Across the Global 2000, unplanned downtime drains an estimated $400 billion every year. When the number is that large, it starts to feel like the whole job.
July 2024 changed that for me, at least in how I articulate what was already nagging at the back of my thinking. A single faulty configuration update, pushed to millions of endpoints, grounded airlines, hospitals, banks, and payment rails worldwide. Healthcare losses alone reached $1.94 billion. Almost every affected system was highly available by design: redundant, multi-zone, load-balanced, uptime dashboards green for months. Availability told us nothing about the failure that actually mattered.
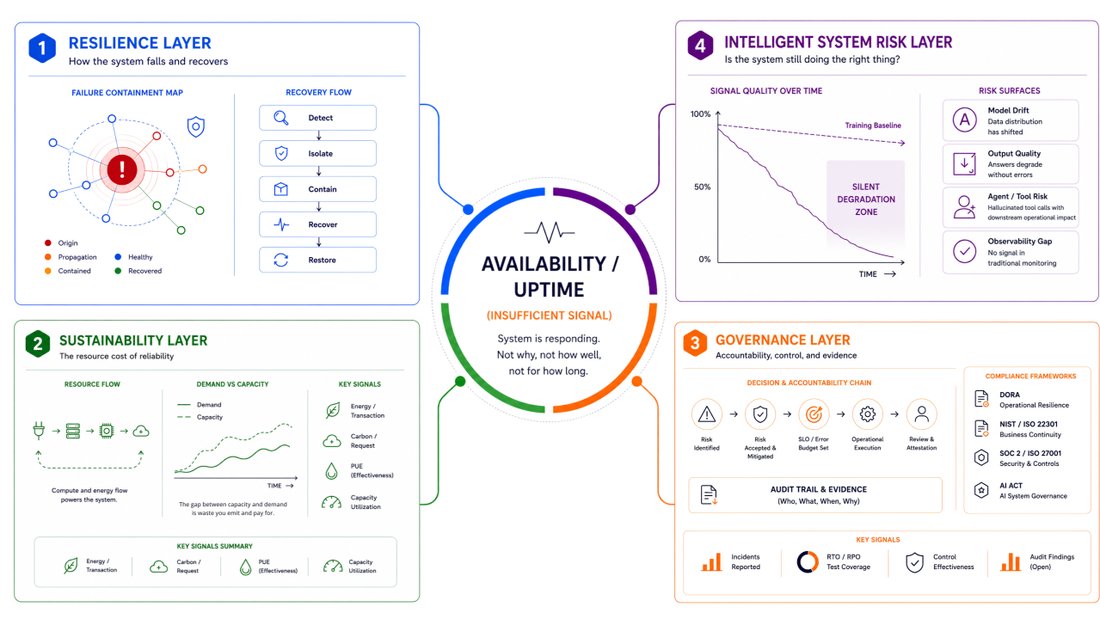
My doctoral research on modern engineering practices and operational efficiency gave me the framework to put words to what I had been seeing in practice for years. The conclusion I keep arriving at is not a comfortable one for a field that has spent two decades building SLO dashboards: uptime is necessary but it is no longer sufficient. Four things sit outside what availability can measure. Resilience. Sustainability. Governance. Intelligent-system risk. All four are showing up in real production environments right now, and most reliability programs are not instrumented for any of them.
Resilience: not whether the system stays up, how it falls
Availability is a presence metric. Is the system responding? Resilience is a behavior question. When something breaks, and it will, how much of the blast radius does the system contain on its own, and how fast does it recover without humans touching individual machines?
A payment service can hold 99.99 percent availability for a full year and still be brittle if its failure mode is to reject every transaction the moment a downstream dependency slows. Fail closed under load is not a resilient service. A resilient service sheds load, serves stale but safe responses where it can, trips circuit breakers, and keeps a degraded core alive for the transactions that matter most.
The 2024 global outage was this exact failure. The affected systems did not lack redundancy. They lacked a fast, automated recovery path. Remediation meant touching machines by hand, one by one, at scale. Mean time to recovery, blast radius, error-budget burn rate, and the shape of degradation under load do not appear on an uptime SLA. They are the metrics that would have told us something useful that day.
Sustainability: the resource cost of reliability
This one I feel more personally, because I have been in the room where the decision gets made wrong. Every additional nine is bought with redundancy: more servers, more replicas, more always-on capacity. That is more electricity and more carbon, at a scale that is no longer trivial to wave away. The IEA put global data center consumption at roughly 485 terawatt-hours in 2025, up 17 percent in a single year. AI-focused facilities grew around 50 percent. Ireland's data centers already draw more than a fifth of national electricity. Virginia's draw more than a quarter of the state's grid.
I have sat in architecture reviews where active-active across three regions was specified for workloads that could safely run active-passive, not because a risk analysis demanded it, but because nobody wanted to be the engineer who signed off on less redundancy if something went wrong later. The carbon cost of that choice was never raised, not once. Sustainable reliability means treating energy per transaction and carbon per request as real engineering signals, and right-sizing redundancy to actual risk rather than to institutional anxiety about being blamed. The most reliable architecture and the most wasteful one are often the same design. That is not a defensible place to stay.
Governance: accountability, control, and evidence
For most of SRE history, an SLO was an internal target, useful inside the team, invisible outside it, with no particular accountability attached beyond the engineers who wrote it. In financial services, where I spend most of my working life, that is now law. The EU Digital Operational Resilience Act applied to financial entities in January 2025. Operational resilience, incident reporting, and tested recovery are regulatory obligations now, not engineering preferences. The EU AI Act layers further requirements on top for high-risk systems. The direction across all of it is the same: being available is not enough, you must demonstrate it, with audit trails, documented recovery objectives, and evidence that failover was actually tested rather than just planned.
This forces clarity on questions that SRE teams have left implicit for years. Who owns the error budget. Who is allowed to spend it. Who signs off on accepted risk. How an incident gets reconstructed after the fact for a regulator who was not in the room. An SLO with no owner and no audit trail is a wish, not a commitment. That distinction now has legal weight behind it.
Intelligent-system risk: is the system still doing the right thing
This is the one that worries me most, partly because the failure mode is the hardest to see. Traditional reliability assumes deterministic systems: same input, same output, every time. When something fails, it fails loudly, with exceptions, timeouts, and errors you can alert on and page someone for.
Machine learning systems break that contract. Production models lose accuracy over time through concept drift and data drift. The world changes, the model does not update, and the outputs quietly degrade with no page sent to anyone. The AI Incident Database logged roughly a 50 percent year-over-year rise in reported incidents into 2024, and 2025 surpassed the prior full year within ten months. Multi-agent systems are harder still, with production failure rates in the 41 to 87 percent range in the absence of deliberate fault-tolerance design.
What unsettles me about this is the silence. A fraud model whose precision has been decaying for three months. An agent that hallucinates a tool call and then acts on the result. An inference endpoint quietly rate-limited into low-quality fallbacks with no signal surfaced anywhere in the stack. Uptime reads 100 percent, the dashboard is green, and the system is failing at the thing it was actually deployed to do. Nothing in the traditional reliability toolbox is looking for that. Drift monitors, output-quality SLOs, confidence scoring, continuous evaluation in production, and human-in-the-loop fallbacks for decisions that carry real consequences are not optional additions for AI systems. They are table stakes. Watching a process stay alive tells you nothing about whether its answers are still right.
Where this goes
I am not arguing that availability stops mattering. It matters enormously, and the $400 billion figure is real and the incentives behind it are not going away. What I am arguing is that availability alone is increasingly the wrong thing to be optimizing for. A system that is always up, always green, always meeting its latency SLOs, can still fail catastrophically on resilience, sustainability, governance, and output correctness simultaneously. The organizations that will operate well in the next decade are the ones that figure out how to instrument and govern all four axes, not just the first one.
My doctoral research is building the framework for what that looks like in practice, summarized on the Research page as the four-axis reliability model. This series works through it, one axis at a time, drawing from patterns observed across eighteen years of enterprise reliability work.
Release governance and evidence
How release decisions are actually made in large regulated organizations, why fragmented evidence is a governance risk, and how frameworks like EGRG turn delivery signals, telemetry, and SLO state into auditable decisions.
LinkedIn long-form
From Vanity Metrics to Decision Metrics: An SLO Framework for Enterprise SRE
Most organizations invest heavily in dashboards, monitoring tools, and reliability reporting. Yet many SLOs never influence a single engineering decision. A reliability metric has value only when it changes behavior, whether that means slowing a release, prioritizing technical debt, allocating resources, or triggering an operational response. A metric you never act on is just expensive decoration. The test I keep coming back to is simple: if this metric breaches tomorrow, what decision will change? If nothing changes, it is not a decision metric. It is a vanity metric.
SLOs are reported, not consumed
Availability shown once a month in a deck, never checked when a change ships, tracked at the server rather than at the experience the customer actually gets, is a vanity metric. It can stay green while real users hit errors and quietly leave. The real test is whether breaching it changes what an engineer does tomorrow, and whether anyone is actually allowed to trade the budget for a slower, safer release.
Choose SLIs the user would recognize
An SLI is a proxy for a promise to a user. Most teams pick what is easy to collect, measured at the server, rather than what the user actually feels at the edge of a real journey like logging in, paying, or searching. A good SLI moves when users are hurt and stays steady when nothing is wrong, with every event unambiguously countable as good or bad. If the user would not notice it move, it is the wrong SLI.
Error budgets are burn rate, not a balance
A 99.9 percent target over 30 days is roughly 43 minutes of budget for the month. The number matters far less than how fast it is being spent. Burning that budget in a single hour, something like fourteen times the sustainable rate, should wake someone up. A steady threefold drain is a ticket to fix, not a 3 a.m. page. Multi-window alerting, short and long windows together, is what keeps that distinction sharp instead of noisy.
When the budget is gone, the policy decides
An SLO without a written policy is a suggestion. The value is the consequence agreed before the incident, not argued during it: ship features at full velocity when the budget is healthy, move reliability work ahead of the roadmap when it is running low, freeze features when it is gone until reliability is paid back. A target breached every single month is not a discipline problem. It means the target itself is wrong and needs fixing.
Run SRE as a product, not a queue
A reliability function that only takes tickets stays permanently under-resourced. Treated as a platform, with engineering teams as customers rather than requesters, a roadmap instead of a queue of fires, and paved paths that make the reliable way the easiest default, adoption becomes the metric that matters. Forced adoption is the signal that it is not a product yet.
Observability fails on adoption, not tooling
Across a large estate, OpenTelemetry rollouts stall on the same blockers every time: instrumentation debt in legacy applications never wired for traces, tool sprawl with no single source of truth, and high-cardinality data that balloons the bill with no clear owner. Teams own the bill, but nobody owns the data quality behind it. It is an ownership and cost problem, not a tooling one.
Make SLOs the evidence at the gate
Reliability data has to enter the governance record. Error-budget status feeding a release go or no-go decision directly, with an audit trail recorded behind every gate call, is what turns an Engineering Governance and Release Gate into something that can be defended to a regulator rather than argued about after the fact. When someone asks why a release shipped, the error budget is the answer.
Reliability is a decision loop, not a dashboard
SLOs that are not reviewed decay into vanity within a quarter. A weekly look at burn and active risk, a monthly check of target against reality, a quarterly re-derivation of SLIs from current user journeys, and an update to the error-budget policy after every incident is what keeps them decision-grade. SLOs without a governance record behind them are just dashboards with opinions, and reliability reviewed once a month is reliability managed once a month.
Taken together, this is what high-performing teams are actually doing: defining SLIs that reflect real user experience, tracking error budget burn rate instead of static thresholds, establishing clear policies before incidents occur, treating SRE as a product with internal customers, driving observability adoption through ownership and accountability, using reliability data as evidence in governance decisions, and building review loops that keep the metrics relevant. Reliability data that never reaches a decision is not measurement. It is theater with a green light.
LinkedIn long-form
The Failures Your Dashboard Will Never Show You
Eighteen years inside regulated enterprises taught me one thing no certification does. The failures that cost the most are almost never the ones your dashboards show you. Uptime reads 100 percent. The graph is green. The system is quietly failing at the exact thing it was built to do. Three patterns I keep coming back to.
An SLO nobody enforces is just decoration. Tracking an error budget means nothing if breaching it changes no behavior. A real policy blocks new feature releases until reliability climbs back above the line. No debate, no Slack message asking teams to slow down, just a gate that removes the choice. The gap is almost never technical. It is governance, and most organizations do not have it.
Defensive over-engineering has a hidden bill. Extra regions and idle capacity added without measuring the actual risk burn real cash and carbon. That is anxiety-driven development. The engineer over-specifying redundancy is not being reckless. They are protecting themselves from the post-mortem where someone asks why they chose less. The carbon cost of that choice never comes up. It should. Most of those workloads could degrade gracefully instead.
AI fails quietly. SRE gets the page. A model drifts. An agent hallucinates a tool call and acts on it. Uptime still reads 100 percent. Nothing in the traditional stack is looking for any of that. When it floods a core service at three in the morning, the on-call engineer gets paged. The data scientist who shipped the model does not. The guardrails these systems need are reliability engineering work, and most teams have not started building them.
We keep building comfortable illusions of control and then optimizing the illusion. The discipline gets more honest when it starts measuring what is actually behind it.
Sustainable and financially responsible operations
Sustainable software engineering, GreenOps, and cost as an engineering signal. Why operational efficiency, energy footprint, and long-term business value belong inside reliability practice rather than beside it.
LinkedIn long-form
Your DevOps Pipeline Is Already a Sustainability Program
During my doctoral research on modern engineering practices and operational efficiency, one pattern kept surfacing that I did not expect to find. The engineering teams making the most measurable progress on sustainability were not the ones that had appointed green committees. They were the ones running tight DevOps discipline: right-sized fleets, lean pipelines, tuned alerting, progressive rollout, carbon-aware routing. The same practices that cut cost and toil were quietly cutting emissions at the same time. Nobody was measuring it that way.
That observation became a thread I kept pulling. The more I looked at how modern engineering practices drive operational efficiency, the more I found sustainability outcomes hiding inside work that engineering teams were already doing, and already getting credit for on the cost side. The carbon saving was real. It just was not being captured. The problem is not that enterprises lack green intent. It is that sustainability is being treated as a separate program with a separate mandate, when the evidence points to it being a byproduct of engineering discipline that already exists.
Separated programs fail for a structural reason. When the sustainability initiative does not control the pipeline, the link between the action and the saving never closes, because the team driving the outcome is not the team measuring it. Meanwhile cost and carbon move together in a way that is easy to underestimate. At enterprise scale, idle compute across hundreds of services compounds into material emissions, not rounding errors, and the savings do not stack in isolation either. Better pipelines, leaner fleets, and smarter deployments reinforce each other over time, so each practice makes the next one easier. The gap has never really been about action. Most teams are already doing the work. Few are capturing the outcome. The greenest practice is often just good engineering, measured.
Seven practices show that pattern most clearly. Each produces a sustainability outcome as a direct consequence of engineering done well. None of them require a GreenOps mandate to deliver results.
Cloud right-sizing and autoscaling
Idle compute is waste an enterprise pays for and emits for at the same time. Horizontal autoscaling adds and drops instances as real demand rises and falls, and right-sizing matches instance type to actual CPU and memory profiles rather than to a conservative guess made at provisioning time. Scaling to zero lets idle services drop to nothing overnight instead of running unattended, and spot or burstable capacity absorbs fault-tolerant workloads that most organizations still run on full-price, always-on instances. At enterprise scale, the blocker is rarely technical. It is that the team owning the deployment configuration is rarely the team paying the cloud bill. Closing that ownership gap is what makes the tooling work.
Build and pipeline efficiency
A 30-second build saving multiplied across 500 daily builds across 50 teams is a material compute reduction, and most organizations have never measured it. Layer and dependency caching, incremental builds, smart test selection, and slimmer container images each look like housekeeping in isolation. At fleet scale, run thousands of times a day, they are compounding efficiency. The saving is not in any single build. It is in the multiplication.
Git discipline
Undisciplined git practices are one of the most overlooked sources of wasted CI/CD compute in large engineering organizations. Every unnecessary pipeline run, stale branch scan, and redundant trigger is compute nobody asked for and nobody noticed. Deleting merged branches, scoping pipeline triggers to the events that actually require them, avoiding redundant runs from duplicate pushes and manual re-runs, and enforcing artifact retention policies are governance decisions as much as hygiene. Every pipeline that did not need to run is compute that was paid for and emitted, and git discipline is where that starts.
Alert-driven provisioning
Noisy alerts drive reactive over-provisioning, and the reason it persists is an asymmetric incentive: teams get paged for under-provisioning but face no consequence for carrying excess capacity. Killing false positives, alerting on user-facing symptoms rather than internal blips, grouping and deduplicating alert storms, and provisioning to measured load rather than to worst-case fear all change provisioning behavior, not just on-call quality. Fear-based buffers are the largest sustained source of idle compute in mature fleets, and the provisioning problem is downstream of the alerting problem.
Zombie environment cleanup
Orphaned development and test environments persist not because nobody thought to clean them up, but because ownership is ambiguous and deleting them requires confidence that nothing still depends on them, confidence most organizations do not have. Ephemeral environments that spin up on demand and tear down after use, a strict expiry on every sandbox with no extension unless a named owner renews it, and infrastructure-as-code reproducibility that rebuilds an environment instead of keeping it warm indefinitely all remove the reason to let one linger. Legacy environments that predate infrastructure-as-code adoption need their own remediation track before teardown is safe. A zombie environment burns compute for no one, and the fix is ownership mapping, not just automation.
Progressive rollout and blast radius
Shipping to a small slice of the fleet first and ramping traffic only as health signals stay green cuts the compute cost of a failed deployment directly, since a contained failure costs a fraction of what a full rollback requires. The larger sustainability gain is second-order. When blast radius is bounded, teams no longer need to carry excess standing capacity as insurance against a full-fleet incident, so the safety buffer shrinks because the risk that justified it shrinks first. At enterprise deployment frequency, the cumulative compute saved by avoiding full rollbacks compounds significantly over time. Fewer failed deploys means less wasted compute, and a smaller blast radius means less standing capacity carried just in case.
Carbon-aware cloud routing
Static region assignment is a legacy architecture decision dressed up as an operational default. Modern cloud governance can route workloads dynamically on traffic patterns, risk-tolerance windows, time-of-day load profiles, and carbon-intensity signals from providers including Electricity Maps and the cloud providers themselves. Batch and reporting workloads can shift to off-peak windows in lower-carbon regions. Failover and cutover rules built for resilience can carry carbon intensity as a weighted factor alongside latency and cost, so that when a resilience event triggers a regional shift, routing toward a cleaner grid is a policy option rather than an afterthought. The infrastructure already supports this. Most teams have not built the routing policy to use it, and framed correctly, carbon reduction arrives as the byproduct of resilience architecture rather than as a separate mandate.
The organizations that will lead on sustainable engineering will not be those that stood up the most ambitious green programs. They will be those that added carbon and compute efficiency as measured outputs of the engineering work they were already running, tracked continuously alongside reliability and cost, rather than treating it as a retrospective claim. Eliminating the waste once produces both the financial saving and the emissions reduction together, because they are the same signal measured from two directions. Right-sized fleets support better alerting thresholds, better alerting supports tighter provisioning, and tighter provisioning reduces the capacity buffers that inflate rollback blast radius in the first place. Each practice makes the next one easier. That measurement, byproduct rather than branding, is what most organizations are still missing.
AI observability and intelligent-system reliability
What observability means for LLM-based and agentic systems, how reliability engineering must adapt to probabilistic behavior, and what enterprises should instrument before autonomous systems reach production.
Published pieces in this theme will be listed here.
Post-quantum and emerging risk readiness
Post-quantum transition considerations from an enterprise reliability perspective: what changes operationally, not just cryptographically, as organizations prepare for quantum-relevant threats.
LinkedIn long-form
Post-Quantum Readiness Is Becoming an SRE Conversation, Not Just a Security One
Most enterprises are treating post-quantum cryptography as a future security problem. It is a present-day reliability problem. When post-quantum migration goes wrong, the failure modes are not cryptographic. They are operational.
Certificates that were never properly discovered or catalogued cannot be rotated when algorithms change. Handshake latency from larger post-quantum keys breaches existing SLOs and trips client timeout thresholds that nobody tested. Broken trust anchors take down authentication flows, identity federation, and every downstream service that depended on them. These are reliability failures. They require SRE mechanisms to govern them, not just cryptographic standards to select.
The exposure is not limited to migration failures either. Sensitive data encrypted today with RSA or ECC can be collected now and decrypted later once a cryptographically relevant quantum computer exists. If your data has a long confidentiality lifetime, your exposure window is already open. This belongs in your risk register today, not in a future planning cycle.
The core problem for SRE and platform engineering leaders is that post-quantum readiness cannot be a one-time upgrade project. Cryptographic assets change every time teams deploy services, rotate certificates, update libraries, onboard vendors, or modify identity flows. A point-in-time inventory decays. What is needed instead is continuous measurement: SLIs for cryptographic inventory coverage and quantum-vulnerable asset ratios, SLOs for migration progress by service criticality, error budgets that bound residual exposure and migration change failure rates, production readiness gates that verify rollback is tested before any post-quantum cryptography change reaches production, and ownership mapping so every cryptographic dependency has an accountable team behind it.
Selecting approved algorithms is necessary. It is not sufficient. Q-Day will behave like a systemic reliability change across an entire cryptographic estate. The organizations ready for it will be those that measured readiness continuously, assigned ownership, and governed it like any other reliability discipline.
Editors: for contributed articles or expert columns in any of these themes, see Contact.